Paper Episode 3: The Autonomy Governor: Risk Score Construction, Calibration, and Failure Modes
The Autonomy Governor: Risk Score Construction, Calibration, and Failure Modes
Part 3 of a series on adaptive autonomy switching in human-autonomous teaming.
From Track Uncertainty to Risk
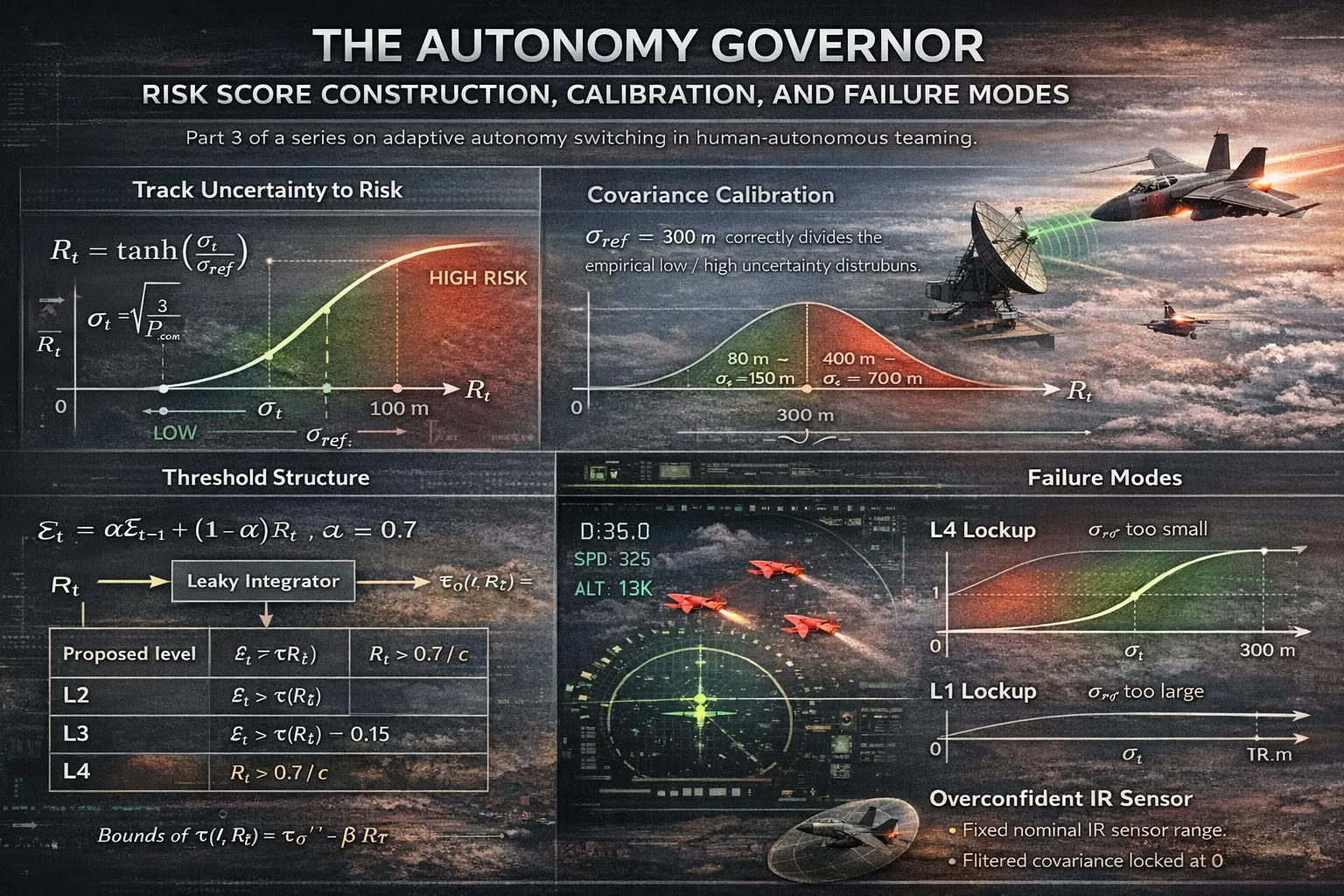
The fusion pipeline produces, at each timestep , a fused position covariance . The governor’s first task is to distill this into a scalar risk signal . The chosen mapping is:
The is not arbitrary. It has three properties that matter here:
- Bounded output: regardless of how large gets, so a diverging tracker does not produce unbounded risk estimates.
- Monotone sensitivity: everywhere, so improvements in tracking quality are always reflected in the risk signal.
- Saturation at both ends: for , (linear, sensitive); for , (saturated, stable). This means the governor does not continue differentiating between “bad” and “catastrophic” tracker states once the track has effectively failed, the risk is maximal and the response is the same.
The calibration constant sets the inflection point of the the uncertainty value at which the governor is operating in its most sensitive regime. Choosing it correctly is the central calibration problem.
The Calibration Problem
The initial value of was set to 50 m, chosen intuitively as “roughly the radar range noise.” This was wrong, and the consequences were total.
With m, a tracker with m produces near-maximum risk at all times, regardless of scenario conditions. The governor locked at for every policy and every sensor quality condition. The experimental design had across all policies, indistinguishable from a fixed- policy. There was no signal to find.
The correct approach is to calibrate against the actual distribution of values produced by the pipeline. Running the sensor stack under nominal (HIGH quality) conditions produces a convergent tracker with m. Under degraded (LOW quality) conditions, ranges over m with intermittent dropouts. The inflection should sit somewhere in the middle of this range not below the minimum, not above the maximum.
Setting m places the inflection point at the boundary between HIGH and LOW quality regimes:
This spread is what the experiment needs. At m, both values map to ; at m, they map to - a range that drives meaningful threshold variation through .
The general principle: must be calibrated against the empirical covariance distribution of your specific tracker and sensor configuration, not derived from sensor noise parameters alone. The relationship between measurement noise, process noise, filter gain, and steady-state covariance is nonlinear and cannot be reliably estimated without running the filter.
Evidence Accumulation
Rather than applying to the threshold directly, the governor accumulates a leaky-integrated evidence signal:
This is a first-order IIR filter on the risk signal. The time constant is steps at s about 150 ms. This serves two purposes. First, it suppresses transient spikes in caused by individual missed detections or single-step covariance blowups. Second, it enforces an implicit dwell time: the evidence cannot change faster than the filter’s time constant, which bounds the switching rate.
Note the difference from the sliding-window formulation in Part 1. A sliding window of length gives equal weight to all past observations and zero weight to older ones a rectangular impulse response. The leaky integrator gives exponentially decaying weight to past observations with no sharp cutoff. In practice the leaky integrator is more numerically stable and easier to tune with a single parameter ().
The Threshold Structure
With and in hand, the level selection follows:
tau = TAU0 if policy == 'evidence_only' else TAU0 - BETA * R_t
if evidence > tau: proposed = 2
if evidence > tau - 0.15: proposed = 3
if R_t > 0.7 / crit_mult: proposed = 4
with TAU0 = 0.6, BETA = 0.3. The level-specific thresholds are:
| Proposed level | Condition |
|---|---|
| L2 | |
| L3 | |
| L4 |
where is the mission criticality multiplier. The L4 condition is driven directly by rather than when risk is sufficiently high, accumulated evidence is irrelevant. The mission criticality parameter shifts this threshold: (HIGH criticality) lowers the L4 threshold to , escalating to full autonomy earlier; (LOW criticality) raises it to , which is above the maximum value of and effectively disables L4 escalation in low-stakes scenarios.
This last point was the source of a sign-inversion bug. The original implementation used R_t > 0.7 * crit_mult instead of R_t > 0.7 / crit_mult. With the multiplication form, HIGH criticality raised the threshold (harder to reach L4), and LOW criticality lowered it exactly backwards. The direction of the effect was correct in the evidence terms but inverted in the risk-override term. The bug was invisible in aggregate metrics (because is computed over all criticality conditions) and only surfaced when stratifying results by mission criticality, where the sign of the adaptation effect was reversed.
Hysteresis
A bare threshold produces chattering rapid oscillation between adjacent levels when hovers near . The standard fix is hysteresis: downward transitions are blocked unless the governor has spent at least HYSTERESIS = 5 steps at the current level.
if proposed > prev_level:
new = proposed # upward: immediate
elif proposed < prev_level:
new = proposed if steps_at_level >= HYSTERESIS else prev_level
else:
new = prev_level
Upward transitions are immediate; the system escalates authority as fast as the evidence warrants. Downward transitions are delayed. This asymmetry reflects the asymmetric cost structure: failing to escalate when the situation deteriorates is more dangerous than maintaining a higher autonomy level for a few extra steps.
With HYSTERESIS = 5 at s, the minimum dwell time before a downward transition is 250 ms. In practice the effective dwell is longer because the evidence signal must also decay through the IIR filter before proposed < prev_level becomes true.
The XAI Log
Every autonomy switch event is serialized to a JSONL file:
{
"t": 47.3, "phase": "Phase2", "level": 3, "level_name": "Conditional",
"switched": true,
"fast_level": 3, "fast_conf": 0.82, "fast_rationale": "2 threats at 35km, R=0.71",
"slow_level": 3, "slow_conf": 0.79,
"slow_summary": "Two converging hostiles at medium range with degraded track quality.",
"slow_visual": "Tracks converging in upper-left quadrant.",
"R": 0.712, "sigma_pos_m": 387.4, "n_threats": 2
}
Non-switch steps are not logged. This keeps the log compact while preserving full fidelity on the events that matter. The log is the primary artifact for XAI analysis: for each switch, we have the reason (fast rationale + slow summary), the quantitative state that triggered it (, , ), and the disagreement structure between the two deciders (fast vs. slow level).
What Breaks and Why
Three failure modes dominated the debugging phase.
Governor lockup at . Caused by too small. The fix is empirical calibration against the actual covariance distribution, as described above.
Governor lockup at . The opposite failure: too large (e.g., 5000 m) maps all realistic values to , keeping and the evidence signal too low to cross it. The governor sees everything as low-risk and stays at the lowest level.
IR overconfidence locking the covariance. When the IR sensor model assigned a fixed nominal range to all angle-only detections, the implied position error was . At close range, this produced m, which propagated through the CI fusion to give , , , and permanent . The fix enforcing with a hard floor at sigma_pos_min = 30 m ensures the effective position uncertainty is always physically interpretable as a function of range and angular noise, and never collapses to zero regardless of sensor geometry.
All three failures produce identical observable behavior: the mean autonomy level is constant across all scenario cells, , and no policy differs from any other in the outcome metrics. Without knowing what the governor should be doing, these failures are silent.
Next: Part 4 - Monte Carlo results: the comparison across policies, Mann-Whitney U tests, and why the mission success metric is the wrong thing to look at.
