Paper Episode 1: Adaptive Autonomy Switching in HAT: Motivation and Formulation
Adaptive Autonomy Switching in Human-Autonomous Teaming: Motivation and Formulation
Part 1 of a series on building and evaluating a risk-dependent autonomy governor for military aviation.
Problem Statement
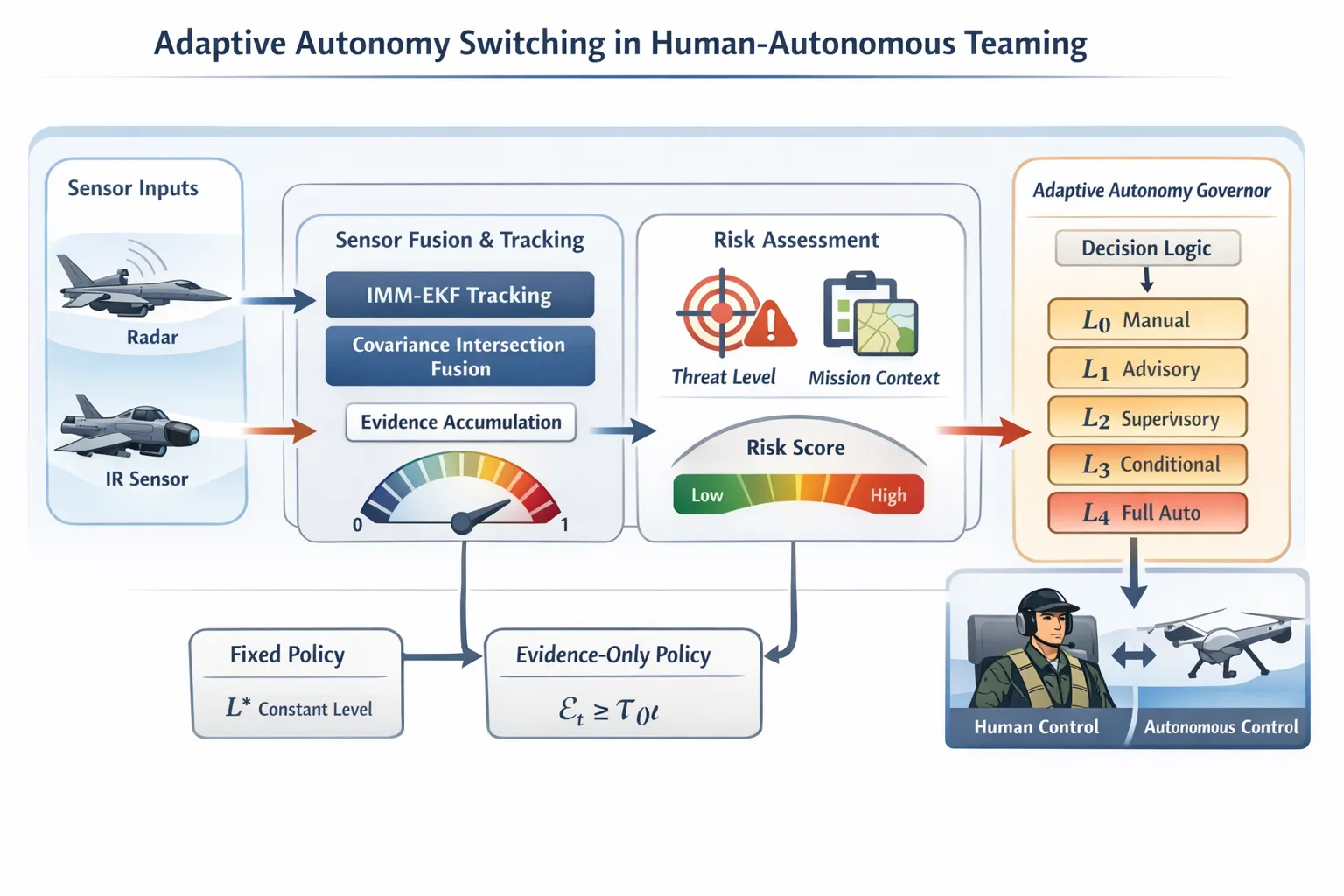
Human-autonomous teaming (HAT) in tactical aviation faces a fundamental allocation problem: which cognitive and executive functions belong to the human, which to the machine, and crucially how should that allocation change as the operational environment evolves?
Existing approaches treat this as a threshold problem over a fixed scalar metric: track quality drops below , autonomy level drops. This is brittle in two ways. First, it conflates sensor degradation with sensor failure a noisy but unbiased radar and a jammed radar demand different responses. Second, and more fundamentally, it ignores situational risk: the cost of under-automation in a terminal threat engagement is not the same as the cost in a low-threat transit leg. A threshold calibrated for one context will be miscalibrated for the other.
The question this project addresses is: can we construct an autonomy governor whose switching policy is provably adaptive to both sensor quality and tactical risk, and what is the performance gain over fixed or risk-agnostic alternatives?
Autonomy Levels and Transition Semantics`
We adopt a five-level taxonomy aligned with the DoD autonomy framework:
| Level | Designation | Human–machine authority split |
|---|---|---|
| Manual | Human executes; system observes | |
| Advisory | System recommends; human decides | |
| Supervisory | System acts; human monitors and overrides | |
| Conditional | System acts within pre-authorized envelopes | |
| Full | System acts without human input |
The semantics of a transition are asymmetric. Upward transitions () increase automation and reduce human cognitive load but increase the risk of acting on a bad estimate. Downward transitions () restore human authority but impose reaction-time costs that may be prohibitive at high threat tempo. A well-designed governor must minimize unnecessary transitions while remaining responsive to genuine state changes a stability-responsiveness trade-off not addressed by instantaneous thresholding.`
Evidence Accumulation
Let be the fused track state (position + velocity) at time , with associated covariance produced by an IMM-EKF fusion stage (described in Part 2). Define the instantaneous track quality:
where is the position subblock of and is a calibration constant. This maps position uncertainty to , with as the tracker converges and as it diverges.
Rather than thresholding directly, the governor accumulates evidence over a sliding window of length :
This suppresses transient measurement outliers and introduces a lower bound on transition dwell time the governor cannot oscillate between levels faster than steps, a necessary stability condition in noisy environments.
Risk-Dependent Threshold
Let be a composite risk score derived from threat proximity, closure rate, and mission phase (the precise construction of is detailed in Part 3). The level at time is selected as:
where the threshold function is:
The parameter encodes the risk sensitivity of the governor. When is high, decreases the governor escalates to higher autonomy levels with less evidentiary support. This is normatively justified: in a high-threat scenario, the cost of delayed automation dominates the cost of premature automation. When , the policy collapses to a pure evidence threshold.
This equation differentiates the risk-dependent policy from two natural baselines:
The fixed policy ignores both evidence and risk. The evidence-only policy responds to sensor quality but is blind to tactical context it will sustain through a terminal engagement as long as the tracker is confident, regardless of whether the human has time to intervene.
Dual-Process Architecture
The governor is implemented as a two-layer decision system, motivated primarily by latency constraints.
The FastDecider operates at every timestep , evaluating against and emitting a provisional recommendation . It is purely rule-based and executes in .
The SlowDecider is a language model (LLM/VLM) invoked asynchronously when either (i) , or (ii) . It receives a JSON-serialized state summary and, in the full pipeline, a rendered situational display image. Its output is a confirmation or veto of .
The FastDecider handles the common case at negligible cost; the SlowDecider is reserved for the decision-relevant minority of timesteps where inference latency is justified. This asymmetry is what makes real-time operation feasible while retaining capacity for deliberate, context-aware reasoning at critical junctures.
Experimental Design and Evaluation Criterion
The evaluation uses a factorial design. The three factors are sensor quality (HIGH / LOW), threat tempo (FAST / SLOW), and mission criticality (), yielding 8 scenario cells . Each cell is evaluated under 4 policies and 100 Monte Carlo runs 3,200 runs total.
The primary evaluation metric is conditional adaptability, defined as the difference in mean autonomy level between degraded and nominal sensor conditions:
A large indicates that the policy escalates autonomy appropriately when the sensor picture degrades. A fixed policy has by construction. The central hypothesis is that the risk-dependent policy achieves significantly larger than the evidence-only policy, particularly under high-criticality conditions.
Conventional metrics such as tracking RMSE or mission success rate are policy-independent in this simulation: all policies share the same sensor fusion backend, so trajectory estimates are identical across policies. This is why aggregate performance metrics are insufficient as evaluation criteria and why conditional adaptability is the correct locus of comparison. The implications of this are discussed at length in Part 4.
Roadmap
- Part 2 - Simulation environment: 3-DOF flight dynamics, radar/IR sensor models, and the IMM-EKF fusion pipeline that produces .
- Part 3 - The governor in detail: construction of , calibration of and , and the failure modes encountered during development.
- Part 4 - Monte Carlo results: the comparison across policies and the statistical argument for the central hypothesis.
- Part 5 - LLM integration: model selection (SmolLM2-1.7B / SmolVLM-500M), vision ablation, and the mock-mode design pattern.
